LLM大模型出现后,如何使用LLM+RAG实现本地化部署的知识库成为热点。
本文将为您提供在Ubuntu 24.04上部署LLM+RAG知识库系统的完整指南,并分享调优技巧,帮助开发者打造高效、私密的AI知识库。
基本信息概述
Ollama的概述
Ollama 是一个开源工具,旨在简化在本地运行大型语言模型(LLM)的过程。它支持多种模型,如 Llama 2、Mistral 等,并提供用户友好的接口,适合开发者或研究人员在本地环境中使用。它的主要优势在于数据隐私和本地化运行,减少对云服务的依赖。
Anything LLM的概述
AnythingLLM 是一个全功能 AI 应用,支持 RAG(检索增强生成)、AI 代理和文档管理。它允许用户选择不同的 LLM 提供者(如 Ollama、OpenAI 等)和嵌入模型,适合构建私有知识库。其桌面版本支持 Linux、Windows 和 macOS,强调本地化运行和多用户管理。
DeepSeek V3 模型概述
DeepSeek V3 是一款由 DeepSeek 开发的开源大型语言模型(LLM), 它采用混合专家(Mixture-of-Experts,MoE)语言模型,总参数量为 6710 亿,每次处理时激活 370 亿参数。 通过仅激活部分专家网络来实现高效计算,降低了推理和训练的计算成本。
DeepSeek-R1-Distill-Llama-70B 模型概述
DeepSeek R1 是由中国 AI 公司 DeepSeek 开发的大型语言模型(LLM),专注于逻辑推理、数学和编码等领域。它采用了混合专家(MoE)架构,总计拥有 671B个参数。
除了发布 DeepSeek R1 模型本身,DeepSeek 还开源了多个蒸馏模型。这些蒸馏模型通过将 DeepSeek R1的知识转移到较小的开源模型中创建,旨在保留大部分性能的同时,减小模型规模并提高计算效率。
QwQ-32B 模型概述
QwQ-32B 是 Qwen 团队(Alibaba Cloud)开发的推理模型,拥有 32.5B 参数,擅长编码和数学推理。模型支持长上下文(高达 131K 令牌),适合复杂任务,但运行需至少 24GB GPU 内存(量化后)。
Bge-m3 嵌入模型概述
Bge-m3 是 BAAI(北京人工智能研究院)开发的嵌入模型,支持多功能性(密集检索、多向量检索、稀疏检索)、多语言(100+ 语言)和多粒度(短句至 8192 令牌文档)。它在多语言检索任务中表现优异,适合知识库的文档嵌入。
部署前提条件
软件环境
- 系统为 Ubuntu 24.04(建议使用最新LTS版本)
硬件要求
- GPU显存不少于16GB; 若没有足够的GPU显存,可使用更低量化版本的模型
- 磁盘空间足够存储模型文件和知识库数据。
部署过程
安装Ollama
详细文档可以参考 Ollama官网文档
安装
- 打开终端,执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh - 启动ollama服务:
ollama serve - 验证ollama版本
ollama --version - 列出本地下载好的模型
ollama list
设置为服务自启动
- 创建用户和组
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama sudo usermod -a -G ollama $(whoami) - 创建服务文件 /etc/systemd/system/ollama.service
sudo vim /etc/systemd/system/ollama.service - 添加数据到文件中
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=$PATH" [Install] WantedBy=multi-user.target - 保存文件修改后,执行
sudo systemctl daemon-reload sudo systemctl enable ollama
配置
- ollama默认运行时,API服务地址为 http://127.0.0.1:11434。如果需要支持其他url访问api,可以配置环境变量
sudo vim /etc/systemd/system/ollama.service - 在文件中[Service]下添加Environment相关配置信息
[Service] Environment="OLLAMA_HOST=0.0.0.0:11434" - 保存文件修改后,执行
sudo systemctl daemon-relLLM sudo systemctl restart ollama
下载LLM模型
下载QwQ-32B模型
- 命令行运行以下命令,等待下载完成
ollama pull qwq - 查看模式是否已经存在
ollama list
下载DeepSeek R1模型
- 命令行运行以下命令,等待下载完成。默认下载的4bit量化的模型
ollama pull deepseek-r1:1.5b //下载1.5b模型 ollama pull deepseek-r1:7b //下载7b模型 ollama pull deepseek-r1:8b //下载8b模型 ollama pull deepseek-r1:14b //下载14b模型 ollama pull deepseek-r1:32b //下载32b模型 ollama pull deepseek-r1:70b //下载70b模型 - 如果要下载非量化的模型,可以使用下面的命令
ollama pull deepseek-r1:32b-qwen-distill-fp16
下载嵌入模型
下载Bge-m3模型
- 命令行运行以下命令,等待下载完成。
ollama pull bge-m3
安装和部署AnythingLLM
Anything LLM有桌面版本,通过页面下载Destop ,下载对应操作系统的版本,安装后可直接运行。
如果需要部署服务端,支持多用户登录,可是使用如下命令
安装
- 设置anything LLM安装目录
sudo mkdir -p /home/anythingllm && cd /home/anythingllm - 下载安装包
docker pull mintplexlabs/anythingllm:master - 设置环境变量
export STORAGE_LOCATION="/home/anythingllm" && touch "$STORAGE_LOCATION/.env" - 运行容器
docker run -d -p 3001:3001 --cap-add SYS_ADMIN -v ${STORAGE_LOCATION}:/app/server/storage -v ${STORAGE_LOCATION}/.env:/app/server/.env -e STORAGE_DIR="/app/server/storage" --add-host=host.docker.internal:host-gateway mintplexlabs/anythingllm:master
配置
-
访问 http://<YOUR_REACHABLE_IP>:3001/ 进行配置
 点击页面左下角图标,进入配置页面,开始Anything LLM配置操作。
点击页面左下角图标,进入配置页面,开始Anything LLM配置操作。 -
配置管理用户
 初始第一次登录时,需要输入用户名和密码,然后进行配置,配置完成后,可以使用http://<YOUR_REACHABLE_IP>:3001/ 进行访问
初始第一次登录时,需要输入用户名和密码,然后进行配置,配置完成后,可以使用http://<YOUR_REACHABLE_IP>:3001/ 进行访问 -
配置LLM首选项
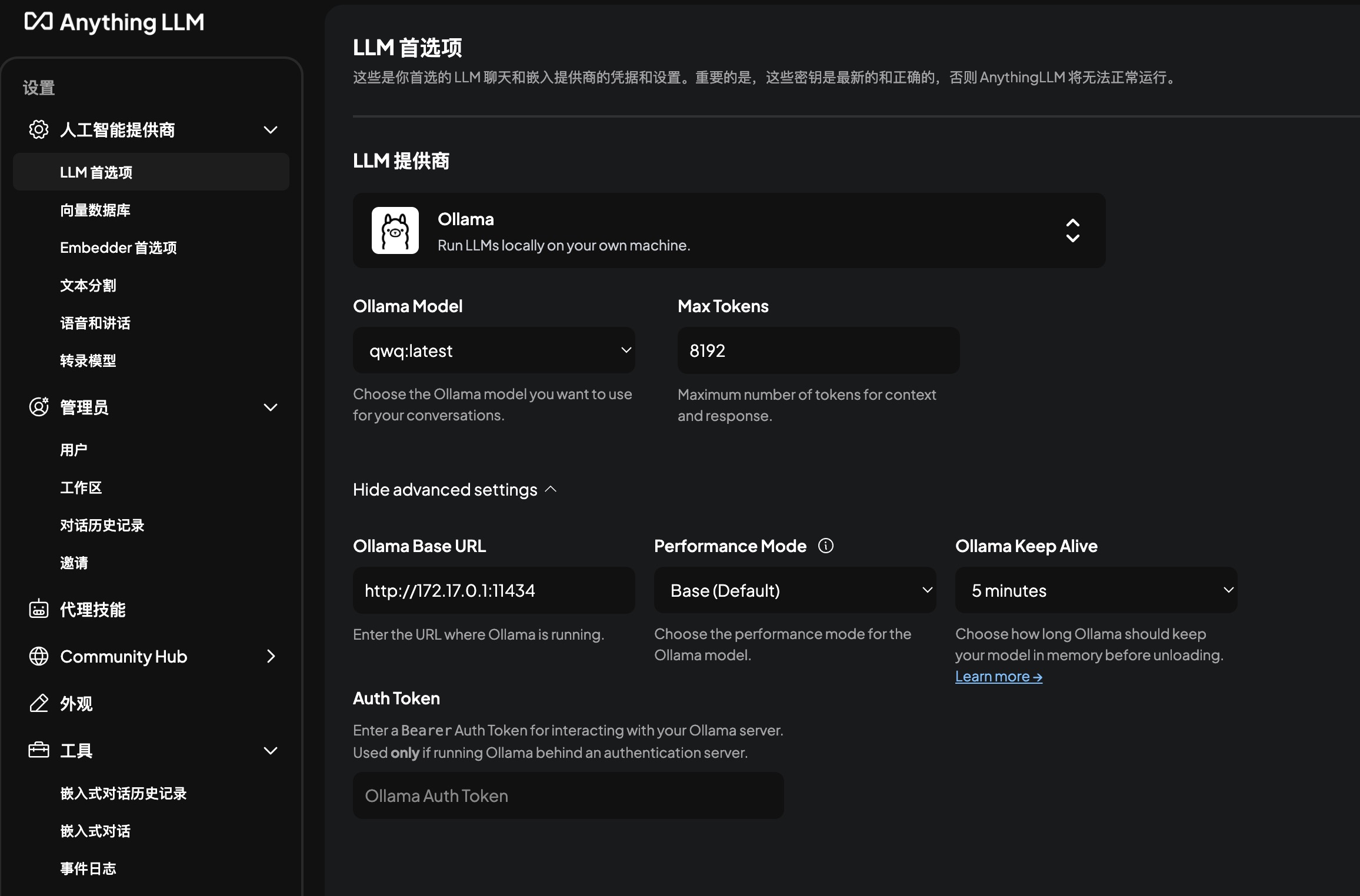 “LLM提供商选项"可以选择Ollama、OpenAI等。
“LLM提供商选项"可以选择Ollama、OpenAI等。- 如果选择OpenAI等外部模型,可配置API Key。
- 如果选择Ollama,注意通过docker运行的Anything LLM,Ollama Base URL为 http://172.17.0.1:11434
Ollama服务如果链接成功,Ollama Model选项中会出现可选择的模型列表。当前选择qwq:latest
-
Embedder首选项
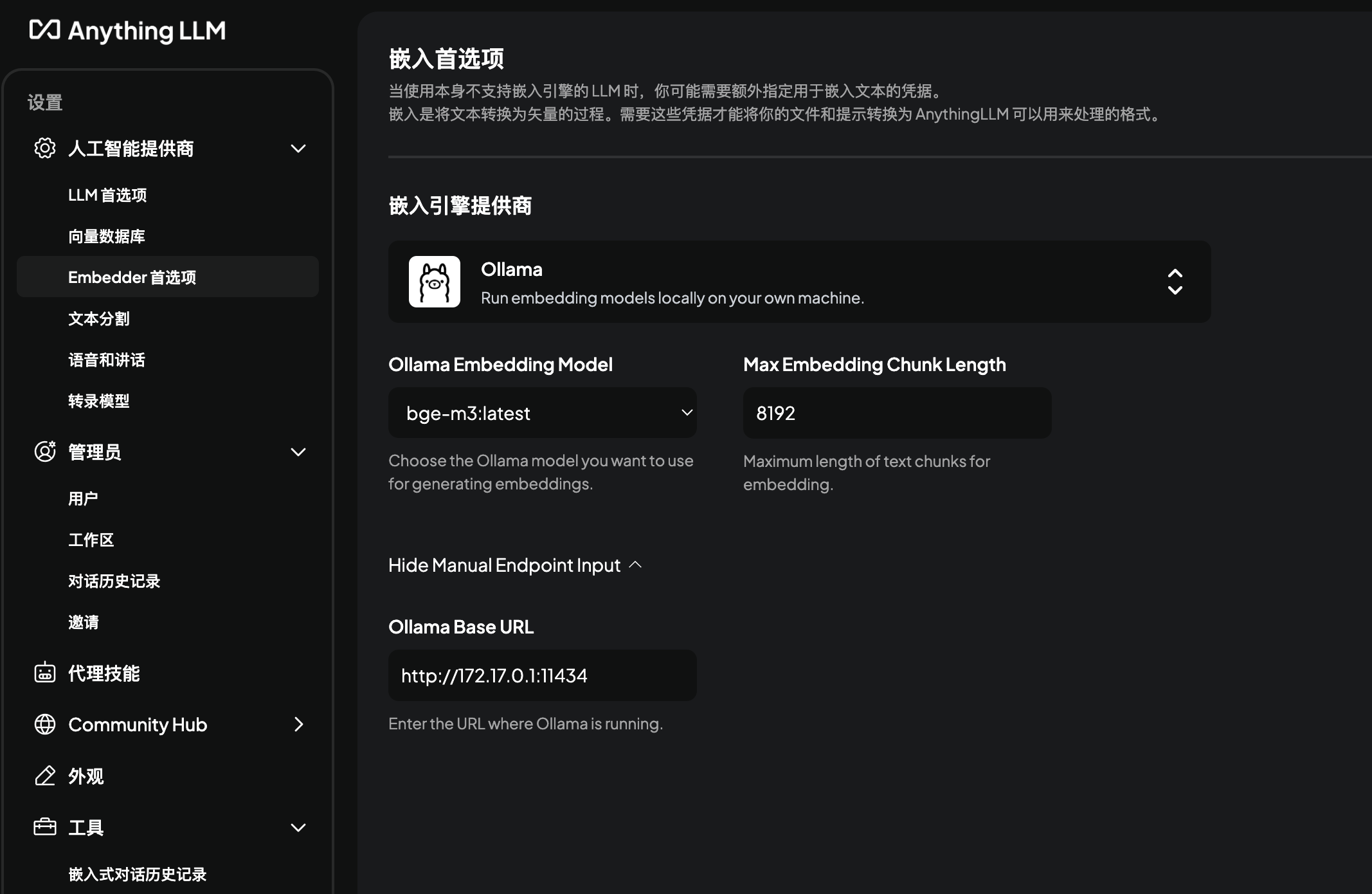 “嵌入引擎提供商"可以选择Anything LLM默认嵌入引擎、Ollama或其他第三方服务等。
“嵌入引擎提供商"可以选择Anything LLM默认嵌入引擎、Ollama或其他第三方服务等。- Anything LLM默认嵌入引擎为 all-MiniLM-L6-v2,该引擎主要针对英语文档,多语言支持较差。
- 如果选择其他第三方服务,如OpenAI等,需要配置API Key。
- 如果选择Ollama,注意通过docker运行的Anything LLM,Ollama Base URL为 http://172.17.0.1:11434
Ollama服务如果链接成功,Ollama Model选项中会出现可选择的模型列表。当前选择bge-m3:latest
-
结束配置,返回主页面
创建本地知识库
在Anything LLM中上传的数据文件,可以被多个知识库选择使用。
新知识库的创建流程为:
创建新工作区 -> 上传或选择已有数据文件 -> 添加数据文件到工作区 -> 数据向量化
数据向量化完成,该工作区的知识库就创建完成。
创建新工作区
-
新工作区
点击“新工作区”按钮,命名新建的工作区。
-
设置工作区内容
 点击图标,进入工作区设置页面。
点击图标,进入工作区设置页面。
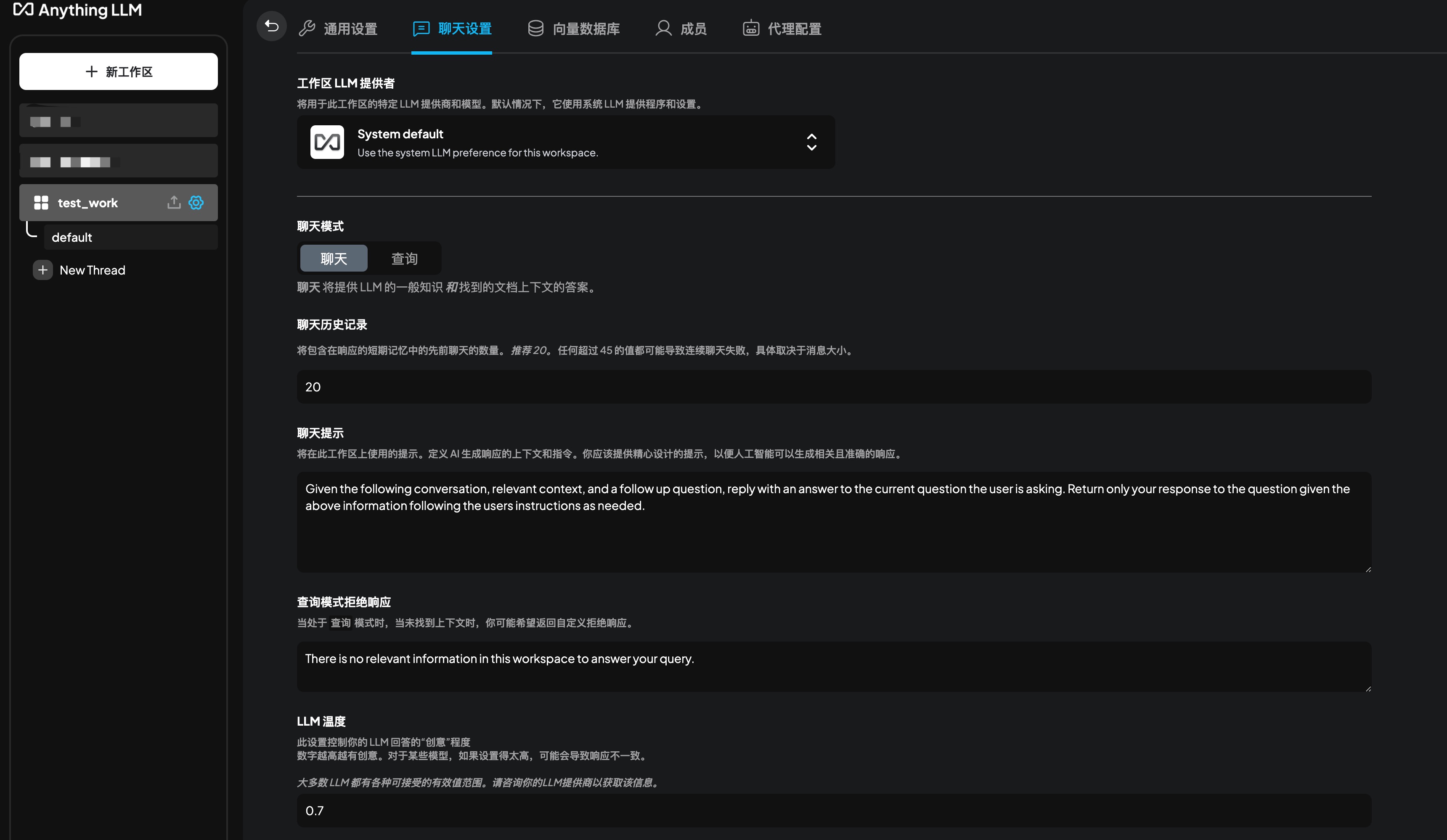 “工作区LLM提供者"选择Ollama,将显示“工作区聊天模型”选项,可以根据需要选择。当前选择qwq:latest
“工作区LLM提供者"选择Ollama,将显示“工作区聊天模型”选项,可以根据需要选择。当前选择qwq:latest工作区其他配置和使用默认值。
上传本地文件
- 打开上传文件对话框
 点击图中图标,弹出上传文件对话框
点击图中图标,弹出上传文件对话框 - 上传文件,完成数据向量化
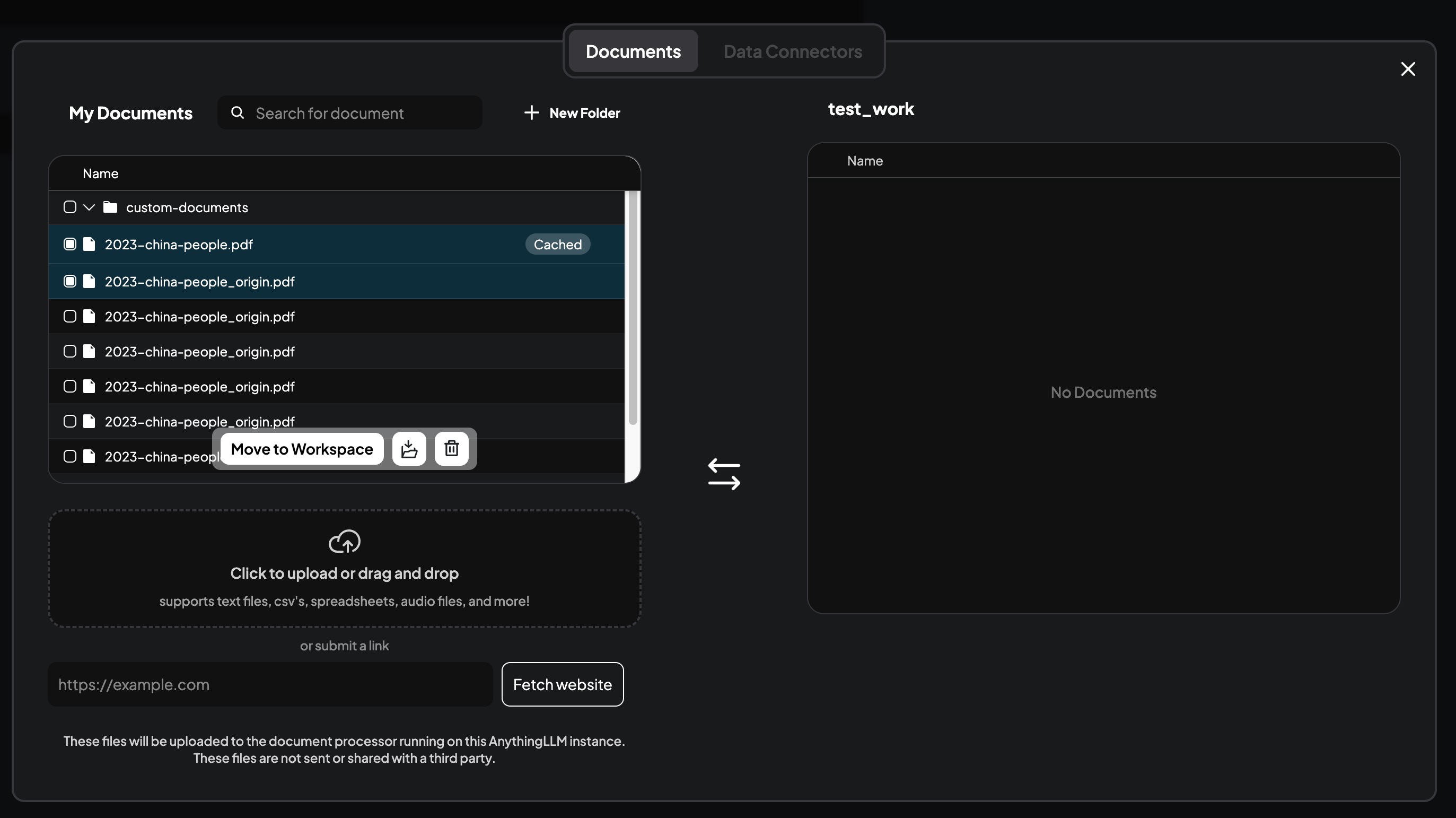
- 将需要导入知识库的文件拖拽到上传文件对话框中。
- 在列表中选择希望导入到工作区的知识库数据文件。
- 点击“Move to WorkSpace”按钮,将选择的文件导入到工作区。
- 点击“Save and Embed”按钮,等待系统对数据进行向量化,完成数据向量化。
调优本地知识库
嵌入向量模型选择
不同嵌入向量模型有不同的特性
| 特性 | all-MiniLM-L6-v2 | BAAI/bge-m3 |
|---|---|---|
| 模型体积 | 25MB | 约1.5GB |
| 硬件要求 | CPU运行,至少2GB内存 | 需要GPU支持 |
| 多语言任务 | 主要针对英文文档 | 支持超过100种语言 |
| 推理速度 (CPU) | 快,适合低端硬件 | 较慢,建议 GPU 支持 |
文本块大小与重叠选择
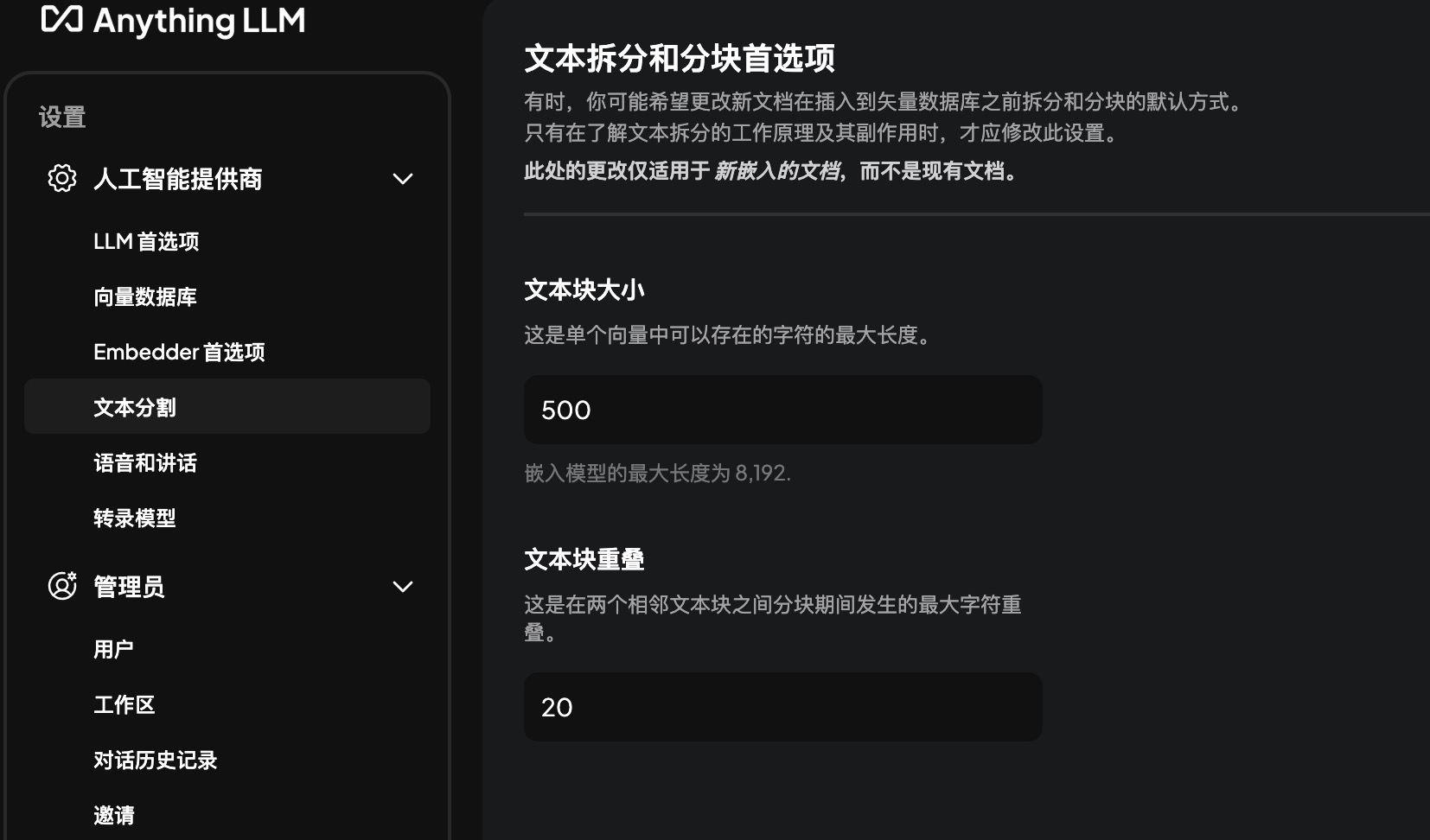
文本块是指文档被分割后的小段,通常因大语言模型(LLM)的输入长度限制而需要分块。
重叠字符串是指相邻块之间共享的部分,旨在保持上下文连续性,避免边界信息丢失。
-
文本块大小的影响 文本块大小直接影响向量的语义表示和下游任务性能:
- 上下文理解: 过小的块可能无法捕捉足够上下文。
- 计算效率: 较大的块需要更多计算资源,输入长度增加会显著提高处理时间。
- 粒度与任务匹配: 较小的块适合需要细粒度信息的任务,如特定信息检索;较大的块适合需要整体上下文的任务,如文档总结。
-
重叠字符串数量的影响 重叠量确保块边界处的上下文连续性:
- 上下文保持: 重叠有助于避免信息丢失,例如一个跨块的句子通过重叠保持完整性。
- 冗余与效率: 过多的重叠(如超过20%)会增加计算成本。
- 任务相关性: 重叠量需根据任务调整,例如信息检索中,重叠可确保查询匹配块边界信息;问答系统中,重叠帮助保持上下文完整性。
文本块大小和重叠量的选择可以根据任务和硬件环境进行调整,不同文本类型需不同策略。例如,技术文档可能需要较小块以捕捉细节,而叙述性文章可能需要较大块以保持故事上下文。
聊天提示优化
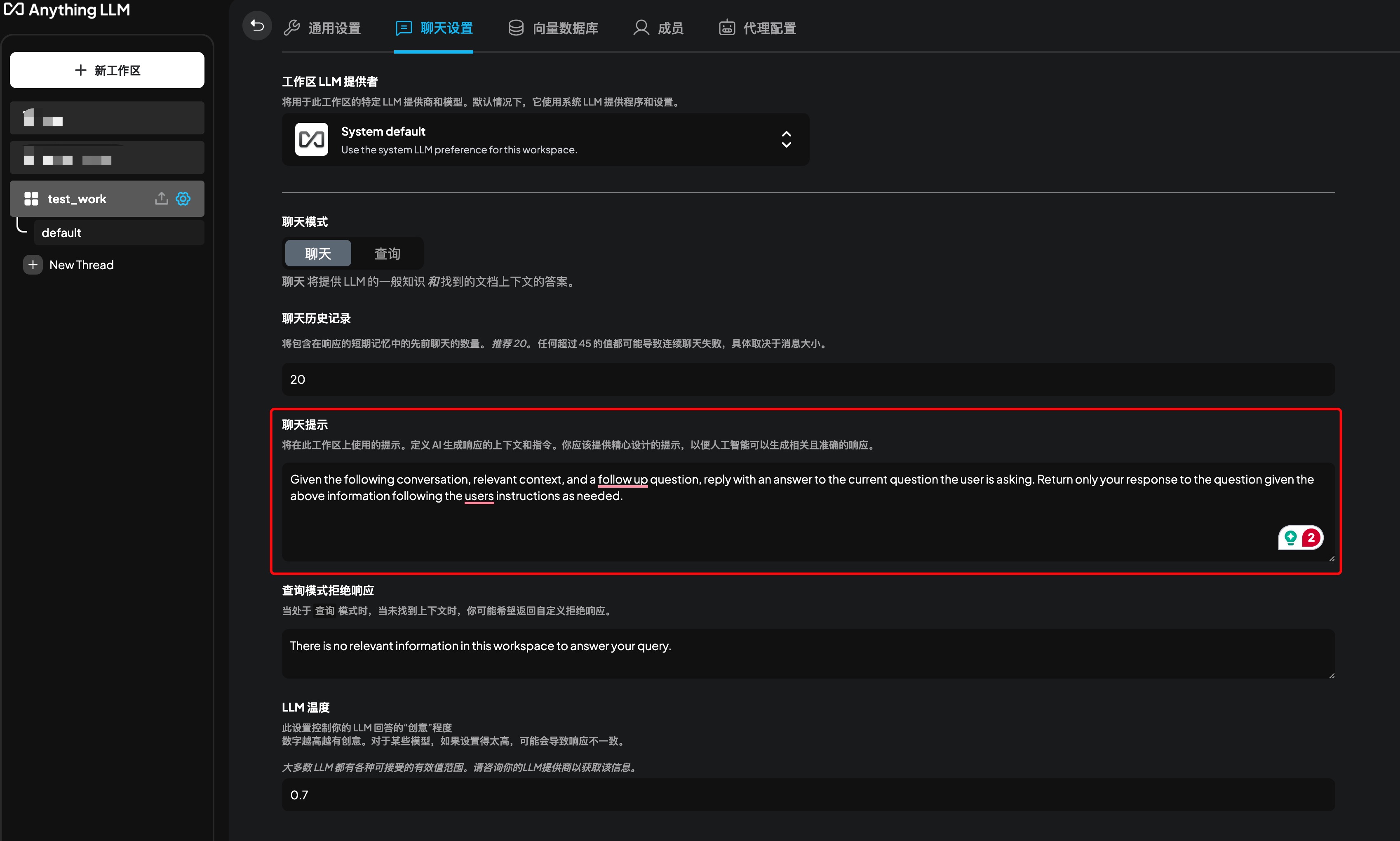 LLM聊天模型的提示词是用来控制模型的行为,可以帮助模型更好地理解和回答问题。
LLM聊天模型的提示词是用来控制模型的行为,可以帮助模型更好地理解和回答问题。
LLM温度设置
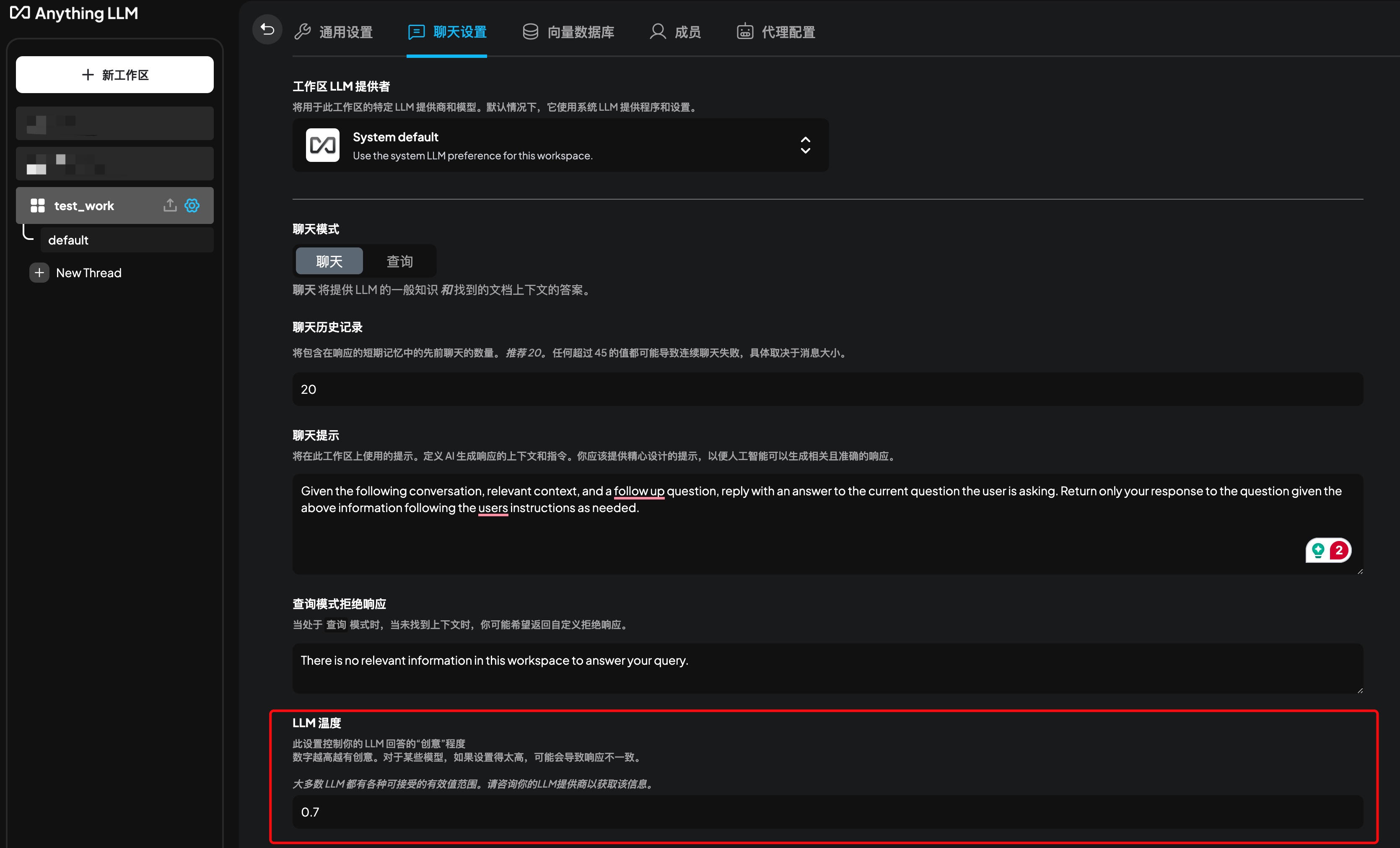 LLM温度设置可以控制模型的随机性,可以更好的控制模型输出质量。
LLM温度设置可以控制模型的随机性,可以更好的控制模型输出质量。
向量数据库设置
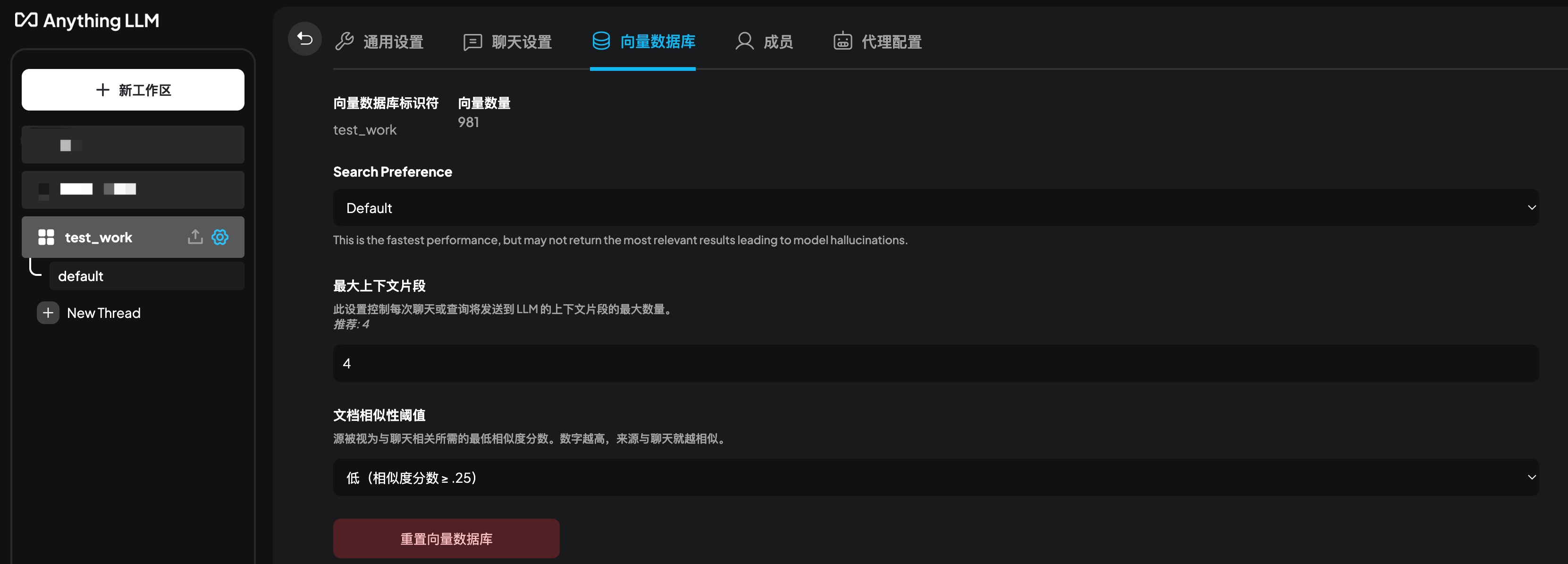
- 最大上下文片段数,控制每次请求的发送到LLM的上下文片段数量,返回的数量越大,LLM获取的数据越多,返回的结果质量越高,但是需要更多的计算资源。
- 文档相似性阈值,控制文档之间的相似性,相似度越高,返回的结果与源文档相关性越强,但是如果检索返回的结果不多,可能导致返回的结果不准确。